Which Of The Following Options Indicates A Non-random Pattern
Onlines
Mar 21, 2025 · 5 min read
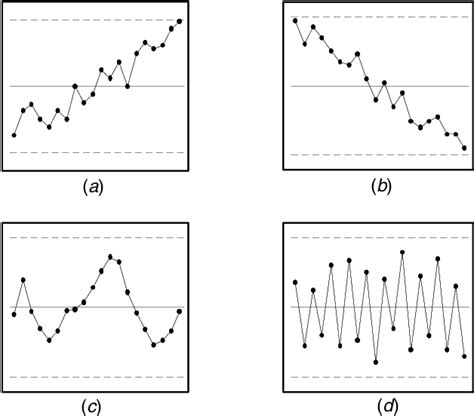
Table of Contents
Which of the Following Options Indicates a Non-Random Pattern?
Identifying non-random patterns within data is crucial across numerous fields, from scientific research and financial markets to cryptography and game theory. Understanding how to distinguish random noise from meaningful structure is a fundamental skill for data analysis and interpretation. This article will delve into various methods and examples to help you discern non-random patterns, focusing on common scenarios and the underlying statistical principles involved.
Understanding Randomness
Before exploring non-random patterns, we need a clear understanding of what constitutes randomness. A truly random sequence exhibits no discernible pattern, predictable behavior, or underlying structure. Each element in the sequence is independent of the others, and the probability of occurrence for each element remains constant. Examples of true randomness are challenging to generate in practice, even with sophisticated algorithms, as true randomness is inherently unpredictable. However, we strive for "pseudo-randomness" – sequences that appear random for practical purposes but are generated using deterministic algorithms.
Identifying Non-Random Patterns: Key Indicators
Several key indicators suggest a deviation from randomness, signaling the presence of a pattern:
1. Predictability:
-
Definition: The ability to accurately forecast future elements in the sequence based on previous elements. A non-random pattern often displays regularities that enable prediction.
-
Example: Consider a sequence of coin flips:
H T H T H T.... This sequence is not random because we can perfectly predict the next flip (it will be opposite of the previous one). A truly random sequence would show no such predictable alternation. -
Statistical Tests: Autocorrelation analysis can detect correlations between successive elements in a time series, indicating predictability.
2. Clustering or Grouping:
-
Definition: Elements of the same type or value appear clustered together more often than expected by chance. This violates the independence assumption of a random sequence.
-
Example: Imagine a scatter plot of data points. If the points are randomly distributed, they will be spread uniformly across the plot. However, if they cluster in specific regions, it suggests a non-random pattern, potentially indicating underlying relationships or subgroups within the data.
-
Statistical Tests: Spatial autocorrelation analysis (for spatial data) and cluster analysis (for grouping similar elements) can reveal clustering patterns.
3. Serial Correlation:
-
Definition: Correlation between elements separated by a specific time lag or distance. This contrasts with randomness where elements are statistically independent.
-
Example: Stock prices often exhibit serial correlation – current prices tend to be influenced by previous prices, indicating a non-random pattern.
-
Statistical Tests: Autocorrelation functions are commonly used to detect serial correlation.
4. Trends and Cycles:
-
Definition: A consistent upward or downward movement (trend) or periodic fluctuations (cycle) over time.
-
Example: Seasonal variations in temperature exhibit a clear cycle, while long-term global warming shows a trend. These are deviations from randomness.
-
Statistical Tests: Regression analysis can identify trends, while spectral analysis can detect cyclical patterns.
5. Non-Uniform Distribution:
-
Definition: The frequency of elements deviates significantly from a uniform distribution. In a random sequence, each element should appear with roughly equal probability.
-
Example: If a die is fair (random), each side should appear roughly one-sixth of the time. If one side appears significantly more often, it indicates a non-random bias.
-
Statistical Tests: Chi-squared tests are used to assess the goodness-of-fit of observed frequencies to a uniform (or any other theoretical) distribution.
6. Runs Tests:
-
Definition: This focuses on the sequence of similar elements (runs). In a random sequence, the length and frequency of runs should follow a specific distribution. Deviations indicate non-randomness.
-
Example: A sequence of coin flips with an unusually long run of heads or tails suggests non-randomness.
-
Statistical Tests: Runs tests assess the number and length of runs within a sequence to detect deviations from randomness.
7. Autoregressive Models (AR):
-
Definition: These models describe a time series based on its past values. The existence of a significant AR model implies a non-random pattern because the future is partially predictable from the past.
-
Example: Modeling stock prices using an AR model often reveals significant coefficients, confirming the presence of non-random patterns.
-
Statistical Tests: Model fitting and parameter significance tests determine the appropriateness and strength of the AR model.
Practical Applications: Identifying Non-Randomness in Different Contexts
Let's examine scenarios where identifying non-random patterns is vital:
1. Financial Markets:
Analyzing stock prices for trends, cycles, and patterns is crucial for investment decisions. Identifying non-random price movements can help in predicting future trends and formulating trading strategies.
2. Cryptography:
Cryptography relies heavily on the generation of random sequences. If a cryptographic algorithm produces a non-random sequence, it becomes vulnerable to attacks and decryption.
3. Scientific Research:
In scientific experiments, the ability to discern random variations from meaningful signals is essential. For example, in clinical trials, distinguishing between treatment effects and random fluctuations is critical.
4. Data Compression:
Data compression algorithms often rely on identifying and exploiting patterns (non-randomness) within data to achieve efficient compression.
Advanced Techniques for Pattern Recognition:
For more complex datasets, advanced techniques such as machine learning algorithms (e.g., neural networks) can help identify non-random patterns that might be missed by traditional statistical methods. These algorithms can uncover intricate relationships and structures within the data that are not readily apparent using simpler methods. However, it's crucial to validate the findings of these sophisticated techniques using appropriate statistical tests and domain expertise.
Conclusion:
The ability to differentiate between random noise and meaningful patterns is crucial for effective data analysis. Various statistical tests and advanced techniques can reveal non-random patterns, enabling us to understand underlying structures, make informed predictions, and develop effective strategies in diverse fields. Remembering that true randomness is rare, and apparent randomness may often hide underlying, yet to be discovered, patterns is key to effective analysis. By carefully examining the evidence and applying appropriate methodologies, we can unravel the secrets embedded within seemingly random data.
Latest Posts
Latest Posts
-
Swear Blanket Crochet Pattern Free Pdf
Mar 21, 2025
-
Is An Acceptable Method Of Communicating With Other Motorists
Mar 21, 2025
-
Beat The Clock Time Management Article
Mar 21, 2025
-
Which Two Concepts Seem Most Closely Related
Mar 21, 2025
-
Which Is The Best Example Of A Vivid Sensory Detail
Mar 21, 2025
Related Post
Thank you for visiting our website which covers about Which Of The Following Options Indicates A Non-random Pattern . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
